Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log data for a single topic partition. It addresses use cases and scenarios such as restoring state after application crashes or system failure, or reloading caches after application restarts during operational maintenance.
We have described the simpler approach to data retention where old data is discarded after a fixed period of time or when the log reaches predetermined size. This works well for temporal event data such as logging where each record stands alone. However an important class of data streams are the log of changes to keyed, mutable data (for example, the changes to a database table).
Log compaction gives us a more granular retention mechanism so that we are guaranteed to retain at least the last update for each primary key. By doing this we guarantee that the log contains a full snapshot of the final value for every key not just keys that changed recently. This means downstream consumers can restore their own state off this topic without us having to retain a complete log of all changes.
The general idea is quite simple. If we had infinite log retention, and we logged each change, then we would have captured the state of system at each time from when it first began. Using this complete log, we could restore to any point in time by replaying the first N records in the log. This hypothetical complete log is not very practical for systems that update a single record many times as the log will grow without bound even for a stable dataset. The simple log retention mechanism which throws away old updates will bound space but the log is no longer a way to restore the current state, now restoring from the beginning of the log no longer recreates the current state as old updates may not be captured at all.
Log compaction is a mechanism to give finer-grained per-record retention, rather than the coarser-grained time-based retention. The idea is to selectively remove records where we have a more recent update with the same primary key. This way the log is guaranteed to have at least the last state for each key.
This retention policy can be set per-topic, so a single cluster can have some topics where retention is enforced by size or time and other topics where retention is enforced by compaction.
how does log compaction work?
Log compaction is handled by the log cleaner, a pool of background threads that recopy log segment files, removing records whose key appears in the head of the log.
The compaction is done in the background by periodically recopying log segments. Cleaning does not block reads and can be throttled to use no more than a configurable amount of I/O throughput to avoid impacting producers and consumers. The actual process of compacting a log segment looks something like this:
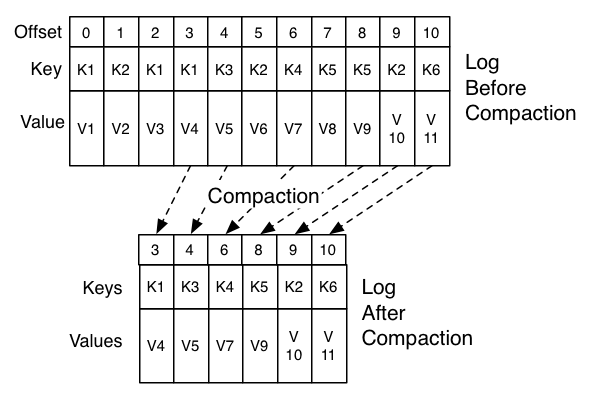
what guarantees does log compaction provides?
Log compaction guarantees the following:
- any consumer that stays caught-up within the head of the log will see every message that is written; these messages will have sequential offsets. The topic’s min.compaction.lag.ms can be used to guarantee the minimum length of time must pass after a message is written before it could be compacted. The topic’s max.compaction.lag.ms can be used to guarantee the maximum delay between the time a message is written and the time the message becomes eligible for compaction.
- ordering of messages is always maintained. Compaction will never re-order messages, just remove some.
- the offset for a message never changes. It is the permanent identifier for a position in the log.
- any consumer progressing from the start of the log will see at least the final state of all records in the order they were written. Additional, all delete markers for deleted records will be seen, provided the consumer reaches the head of the log in a time period less than the topic’s delete.retention.ms setting.