什么是缓存?
广义上讲,凡是位于不同速度存储设备之间,用于协调存取速度差异的,都可以称为缓存。另外,存储复杂计算的结果以避免重复计算也是一种缓存。
缓存分类:
- 静态缓存:用于缓存静态数据,减少后台服务器的压力
- 分布式缓存:用于缓存动态数据,以Redis和Memcached为代表
- 热点本地缓存:对于极端的热点数据查询可以使用热点本地缓存。热点本地缓存内嵌在代码中,用于阻挡热点数据查询对于分布式缓存或数据库的压力,比如Guava Cache
使用缓存的注意事项:
- 缓存适合用于读多写少,并且带有一定热点属性的场景
- 注意数据一致性、缓存容量评估、缓存命中率等问题。一般的,核心缓存的命中率应当在99%以上,非核心缓存的命中率应当在90%以上
缓存读写策略
旁路缓存策略(Cache Aside)
读策略:
- 从缓存中读取数据;
- 如果命中缓存,则直接返回数据;
- 如果未命中缓存,则查询数据库;
- 将查询到的数据写入缓存。
写策略:
- 更新数据库中的记录;
- 删除缓存记录。
为什么写数据时删除缓存而不是更新缓存?因为更新缓存比较麻烦,既要处理并发问题,又要注意数据一致性问题。
旁路缓存策略最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,影响缓存命中率。
读穿/写穿策略(Read/Write Through)
读穿/写穿策略的核心是你只与缓存交互,由缓存和数据库交互。
读策略:
- 从缓存中读取数据;
- 如果命中缓存,则直接返回数据;
- 如果未命中缓存,则由缓存从数据库加载数据。
写策略:
- 查询要写入的数据在缓存中是否存在;
- 如果存在,则更新缓存,由缓存同步更新数据库;
- 如果不存在,那么可以选择(1)写缓存,由缓存同步更新数据库;(2)直接写数据库。
写回策略(Write Back)
写回策略的核心是写入数据时只写入缓存,并且把缓存块标记为“脏”,脏块只有被再次使用时才会将其中的数据写入到下一级存储中。Page Cache、异步刷盘等都是写回策略的应用。
读策略:
- 从缓存中读取数据;
- 如果命中缓存,则直接返回数据;
- 如果未命中缓存,则寻找可用缓存块,判断缓存块是否为脏。如果缓存块为脏,则将脏数据写入下一级存储,并且从下一级存储加载要读取的数据;如果缓存块不为脏,直接从下一级存储加载要读取的数据;
- 标记缓存块不为脏;
- 返回数据。
缓存如何高可用?
客户端方案
在客户端配置多个缓存节点来提高缓存的可用性。一般的,4~6个节点。
写入数据:写入数据时需要做数据分片。一般的,我们使用一致性哈希算法,因为一致性哈希算法可以很好地解决增加或减少节点时缓存命中率下降的问题。
一致性哈希算法:将整个Hash值空间组织成一个虚拟的圆环,然后将缓存节点的IP地址或者主机名做Hash取值后,放置在这个圆环上。当我们需要确定某一个key需要存取到哪个节点时,在环上沿着顺时针方向找到的第一个缓存节点就是目标节点。在增加或减少节点时,只有少量的key会漂移到其他节点上,大部分key命中的节点保持不变,从而可以保证缓存命中率不会大幅下降。
一致性哈希算法的问题:
- 缓存节点分布不均匀:可以引入虚拟节点,即将一个缓存节点计算多个Hash值,对应圆环上多个位置,这样就避免了缓存节点分布不均匀的问题
- 脏数据问题:注意设置缓存过期时间
中间代理层方案
客户端方案的劣势是通用性较差,不方便复用,把客户端方案的高可用逻辑单独抽离出来,就是中间代理层方案。
在应用程序和缓存节点之间增加代理层,客户端的写入和读取请求都通过代理层,代理层内置高可用策略。
中间代理层方案中所有的缓存读写请求都要经过中间代理层,代理层是无状态的,主要负责读写请求的路由功能,并且内嵌了高可用逻辑。
服务端方案
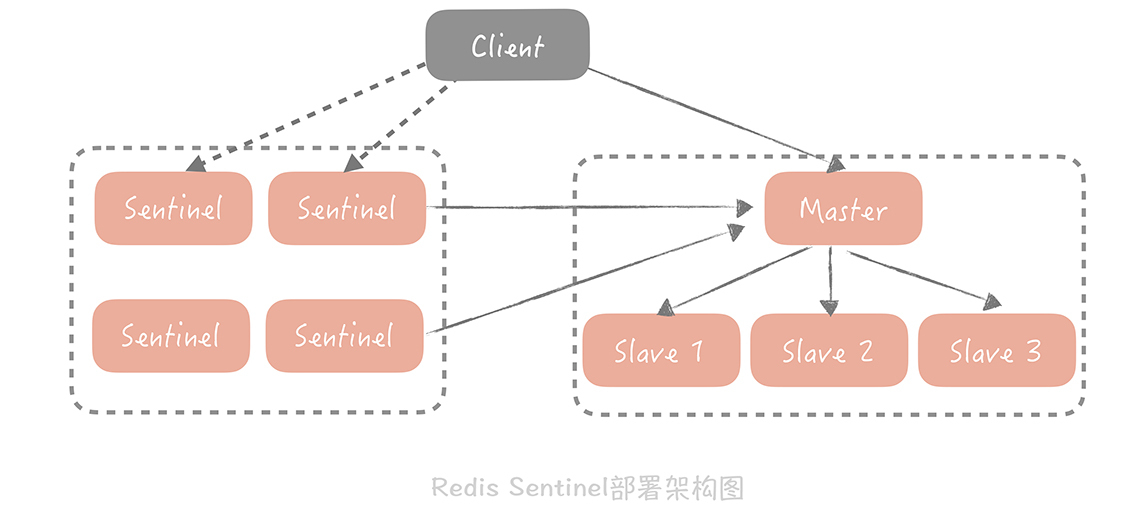
Redis在2.4版本后提出了Redis Sentinel模式来解决主从Redis部署时的高可用问题。
Redis Sentinel也是集群部署的,Sentinel集群节点会监控主节点的状态,当主节点在一定时间内无响应,集群内部仲裁是否进行主从切换,主从切换则将某个从节点提升为主节点,并且把所有其他的从节点作为新主节点的从节点。
缓存穿透
缓存穿透是指未命中缓存而查询数据库。少量的缓存穿透是正常的,但是大量的缓存穿透就可能导致系统崩溃。
缓存穿透有两种典型的解决方案:
- 回种空值
- 布隆过滤器
回种空值
回种空值并设置一个较短的过期时间,这种方案最简单,需要注意的是空值缓存占用缓存容量问题。
布隆过滤器
布隆过滤器基于一个二进制数组和一个哈希算法,可以高效地判断一个元素是否在一个集合中。
使用布隆过滤器需要注意以下两点:
- 哈希碰撞导致的误判
- 不支持删除元素
对于哈希碰撞导致的误判,问题不大,因为碰撞概率较低。当然,可以通过使用多个哈希算法计算多个哈希值,进一步降低碰撞概率。
对于删除元素,可以通过增减计数来实现,但是这样就需要占用更多的空间。