Write-Ahead Logging
简单说就是先写日志,再写磁盘,将写磁盘从随机写转换成了顺序写,这样可以提高更新效率。
redo log
InnoDB特有的日志,在更新语句时,先写redo log,然后更新内存,这样就算更新完成了。后面InnoDB会在合适的时候再将操作记录更新到磁盘。
show variables like 'innodb_flush_log_at_trx_commit';
这个参数设置用于控制redo log的写入策略:
- 设置为0,表示每次事务提交都只写到redo log buffer
- 设置为1,表示每次事务提交都持久化到磁盘
- 设置为2,表示每次事务提交都只写到page cache
redo log是物理日志,记录的是“在某个数据页上做了什么修改”。
redo log是固定大小的,通过wirte pos和check point循环读写。对于TB级别的磁盘,建议将redo log设置为4个文件,每个文件1GB大小。
show variables like 'innodb_log_file_size';
show variables like 'innodb_log_files_in_group';
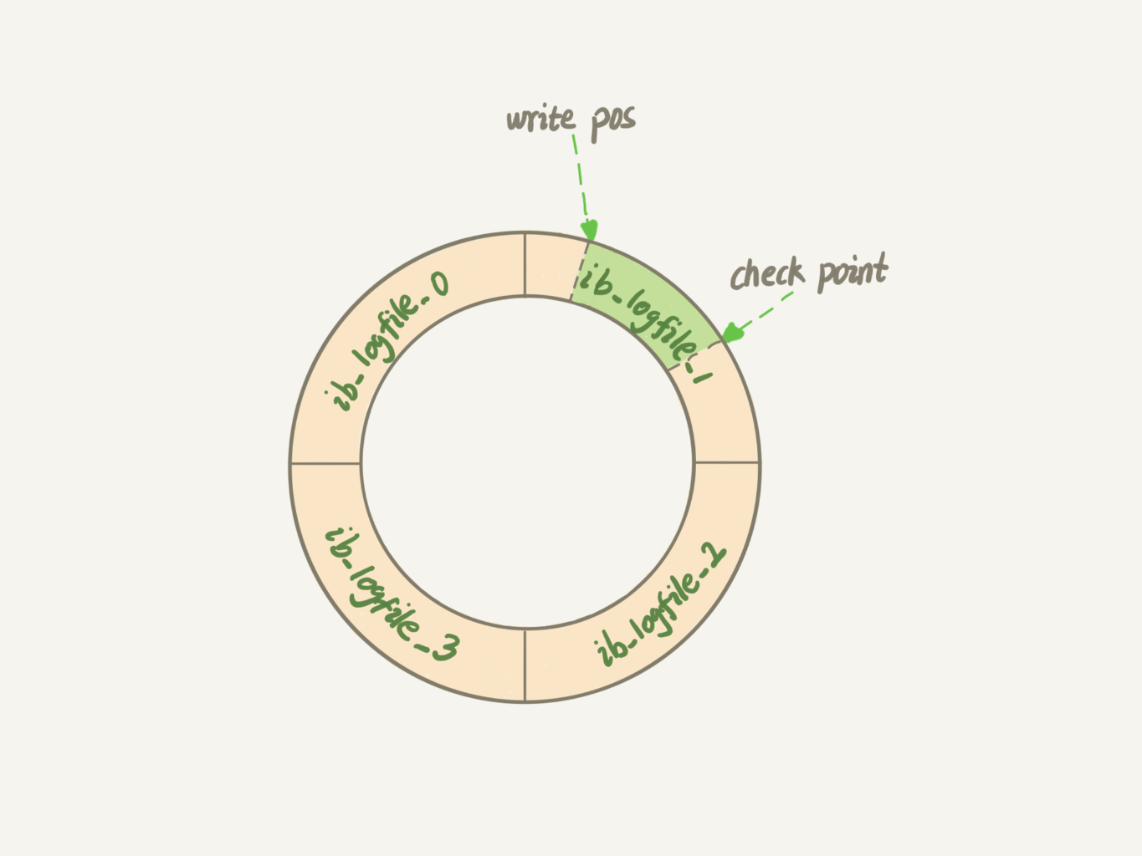
有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录也不会丢失,这种能力称为crash-safe.
binlog(归档日志)
MySQL server层自己的日志。
binlog是逻辑日志,记录的是语句的原始逻辑,比如“给ID=2的这一行的c字段加1”。binlog是可以“追加写”的,写到一定大小后会切换到下一个。
binlog格式:
- statement,记录的是SQL语句原文,可能会出现主备不一致的unsafe情形,比如在主备环境下使用了不同的索引
- row,记录的是实际处理的行信息,不会有主备不一致,缺点是占用空间较大
- mixed,折中方案,MySQL判断是否有可能导致主备不一致,如果有可能,使用row格式,否则使用statement格式
越来越多的场景依赖于把binlog格式设置为row,这样的好处是方便做数据恢复。
数据恢复或新增备库等操作就会用到binlog,一般采用的方法是基于全量备份重放binlog.
binlog写入逻辑:事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中。
show variables like 'binlog_cache_size';
这个参数用于控制单个线程内binlog cache所占内存的大小。
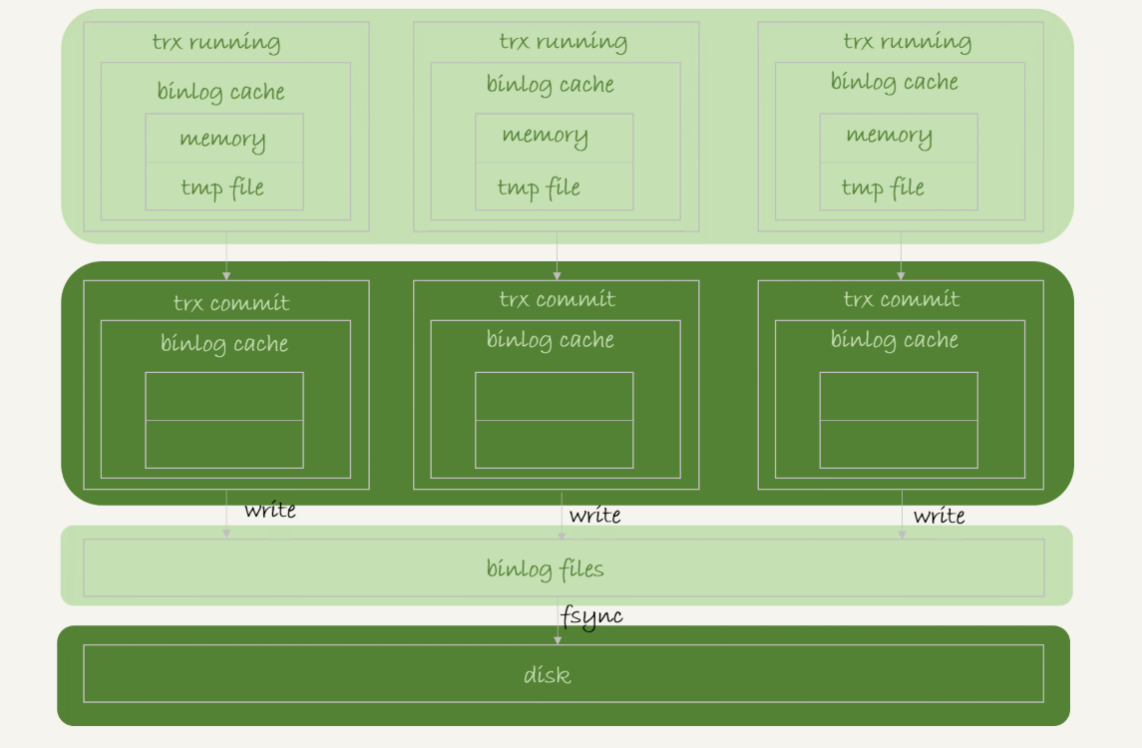
show variables like 'sync_binlog';
write和fsync的时机由sync_binlog参数控制。sync_binlog为0表示每次提交事务都只write,不fsync;sync_binlog为1表示每次提交事务都write并且fsync;sync_binlog为N表示每次提交事务都write,累积N个事务后fsync.
一般的,将sync_binlog和innodb_flush_log_at_trx_commit均设置为1是比较保险的做法。当出现IO瓶颈时,可以考虑将sync_binlog设置为为100到1000中的某个值,风险是如果机器异常重启,会丢失最近的N个事务的binlog日志。也可以考虑将innodb_flush_log_at_trx_commit设置为2,风险是如果机器掉电会丢失数据。
update执行流程
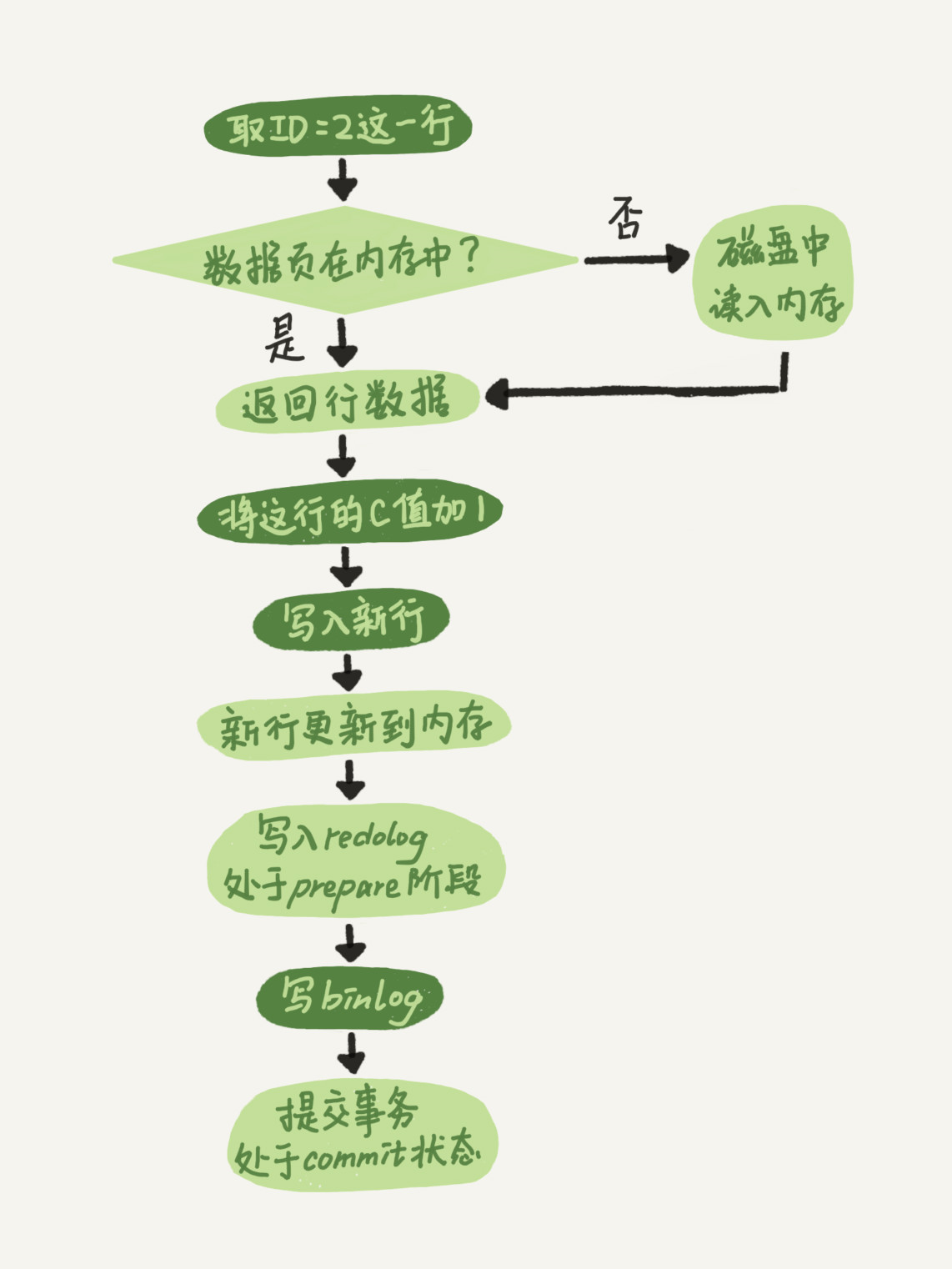
redo log的写入分两个阶段,第一个阶段是prepare状态,写入binlog后,在提交事务时将redo log置为commit状态,这就是两阶段提交。
为什么需要两阶段提交?因为只有这样才能保证在发生异常时,server层和InnoDB的状态是一致的:
- 如果在redo log是prepare状态而写binlog之前发生了crash,由于此时binlog还没写,redo log也未commit,崩溃恢复时这个事务会回滚。binlog没写,也不会传到备库
- 如果在binlog写完而redo log还未commit之前发生了crash,那么崩溃恢复时会判断对应的binlog是否存在并且完整,如果是,则提交事务,否则回滚事务
undo log
在MySQL中,每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,可以得到前一个状态的值。
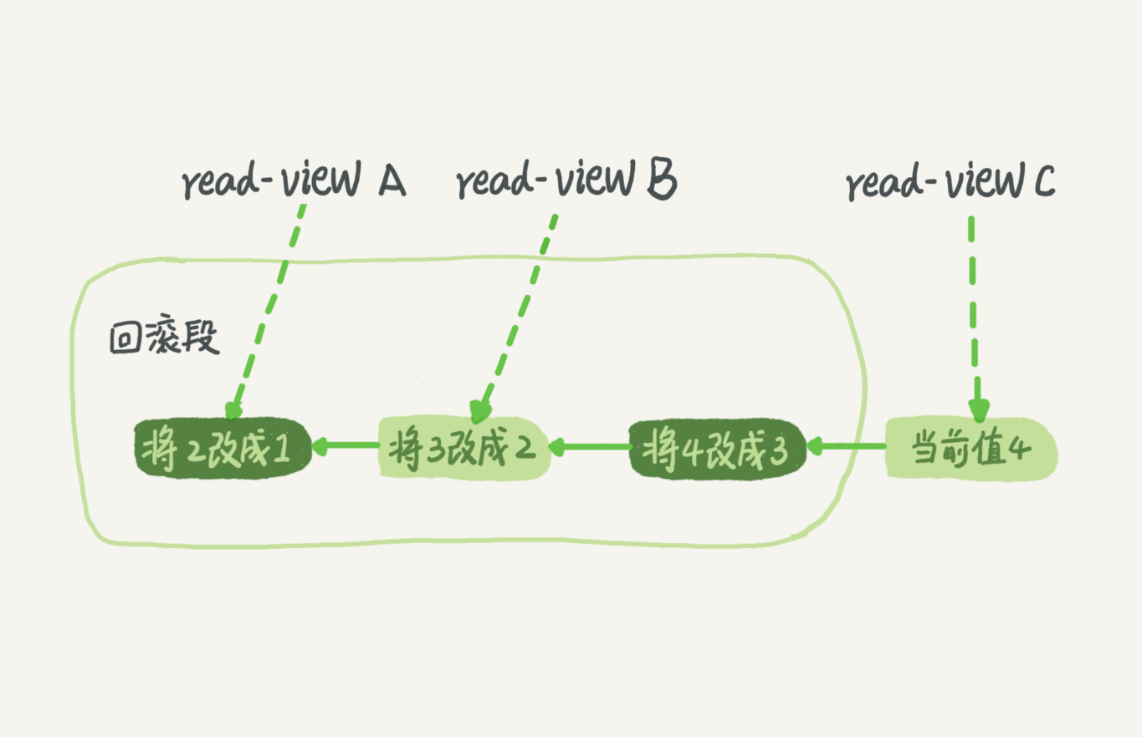
不同时刻启动的事务会有不同的read-view,当没有比某个回滚日志更早的read-view时,回滚日志会被删除。
为什么MySQL会“抖”一下?
你可能碰到过这样的场景,一条SQL语句,正常执行的时候特别快,但是有时不知道怎么回事,会变得特别慢,也很难复现,就像是数据库“抖”了一下。
一个可能的原因是刷脏页(flush)导致的,可能是redo log满了或者内存中脏页过多。
show variables like 'innodb_io_capacity';
这个参数是告诉InnoDB你的磁盘能力,应当参考磁盘的IOPS来设置,如果设置的偏低了,就限制了flush的速度,就会造成脏页累计,影响查询和更新性能。
InnoDB的flush速度会参考两个因素:一个是脏页比例,一个是redo log写盘速度。
show variables like 'innodb_max_dirty_pages_pct';
这个参数设置的是脏页比例上限。
为了避免这种抖动,一方面要合理地设置innodb_io_capacity,另一方面要多关注脏页比例,尽量控制在75%以内。
误删数据
如果使用DELETE误删了数据,可以通过修改binlog后重放恢复原数据。当然,需要binlog_format=row和binlog_row_image=FULL.
如果误删了表或库,那只能通过全量备份+增量日志的方式恢复数。当然,需要有定期的全量备份并且实时备份binlog.
MySQL 5.6引入了延迟复制备库,可以设定某个备库和主库保持N秒的延迟,这样如果发现及时可以降低数据被误删的影响范围。
rm命令误删数据,如果只是集群的某个节点,影响是可控的,HA系统会选出一个新的主库,保证整个集群的正常工作。如何避免整个集群被删除呢?跨机房备份一定程度上可以解决这个问题。